Control Data Flow and File synchronization with EDpCloud
EDpCloud software solution for data flow and file synchronization
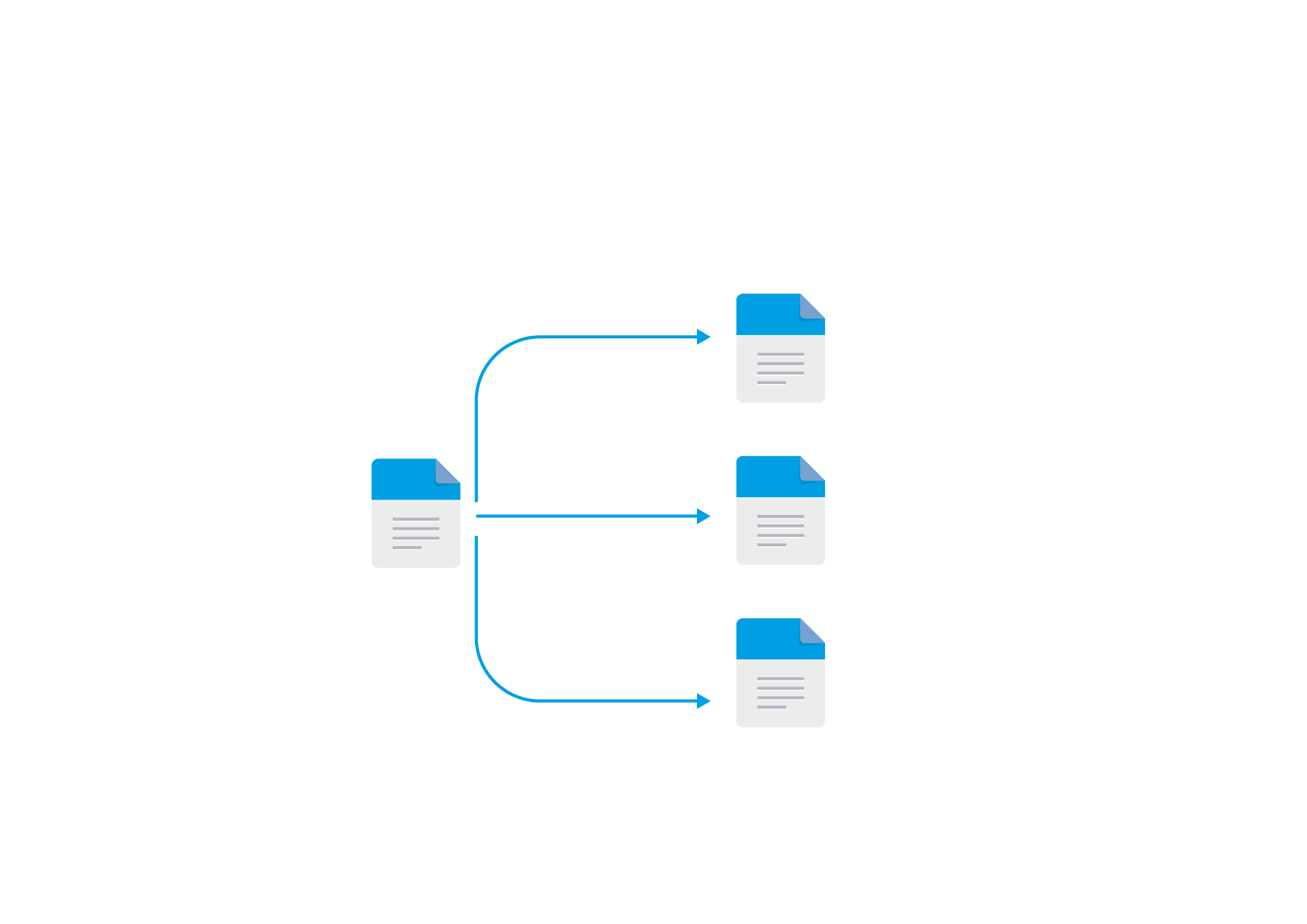
Data flow and file replication between clusters or other nodes
Data can be sent automatically from one cluster to many other clusters, from physical machines or virtual machines or containers.
EDpCloud can be configured to :
- Send data from one node or host to another node, host of VM.
- Send data from many nodes to a single or multiple nodes
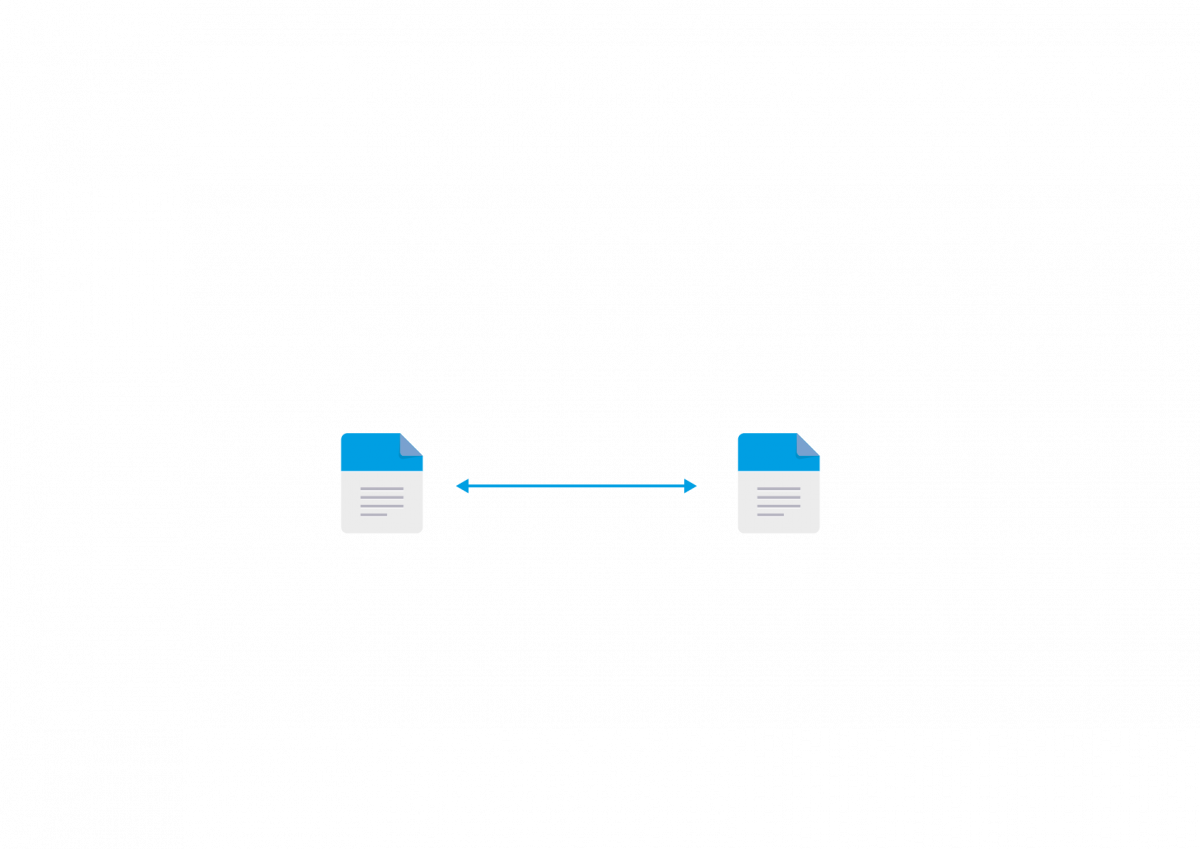
- Send data in a bidirectional fashion to synchronize multiple nodes with each other.
Any data changes in one node or container are synchronized with one or more nodes or containers, thus mirroring two or more nodes or containers in the same or different clusters with each other.
Data flow and transfer from the edge to one or many centers
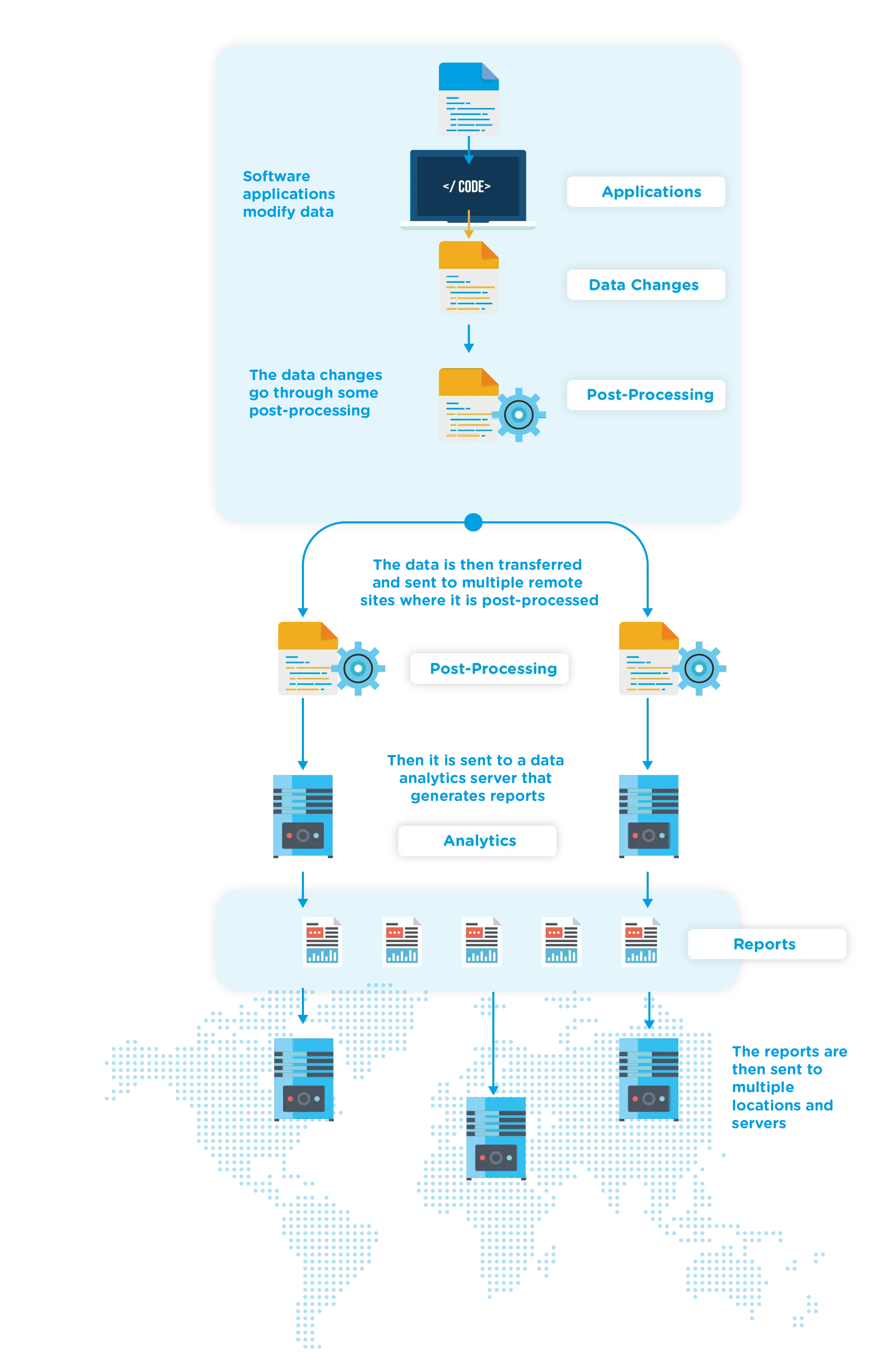
EDpCloud can be configured to send and replicate file changes in real-time, on-demand using a CLI or in a scheduled mode. Applications and scripts can also queue files and directories for replication on demand.
The sending and receiving hosts, virtual machines, or containers can invoke a post or pre-processing script to pass data to other applications for ingestion into databases or for analysis. The receiving end can queue back the processed data and distribute it to the edge or other locations.
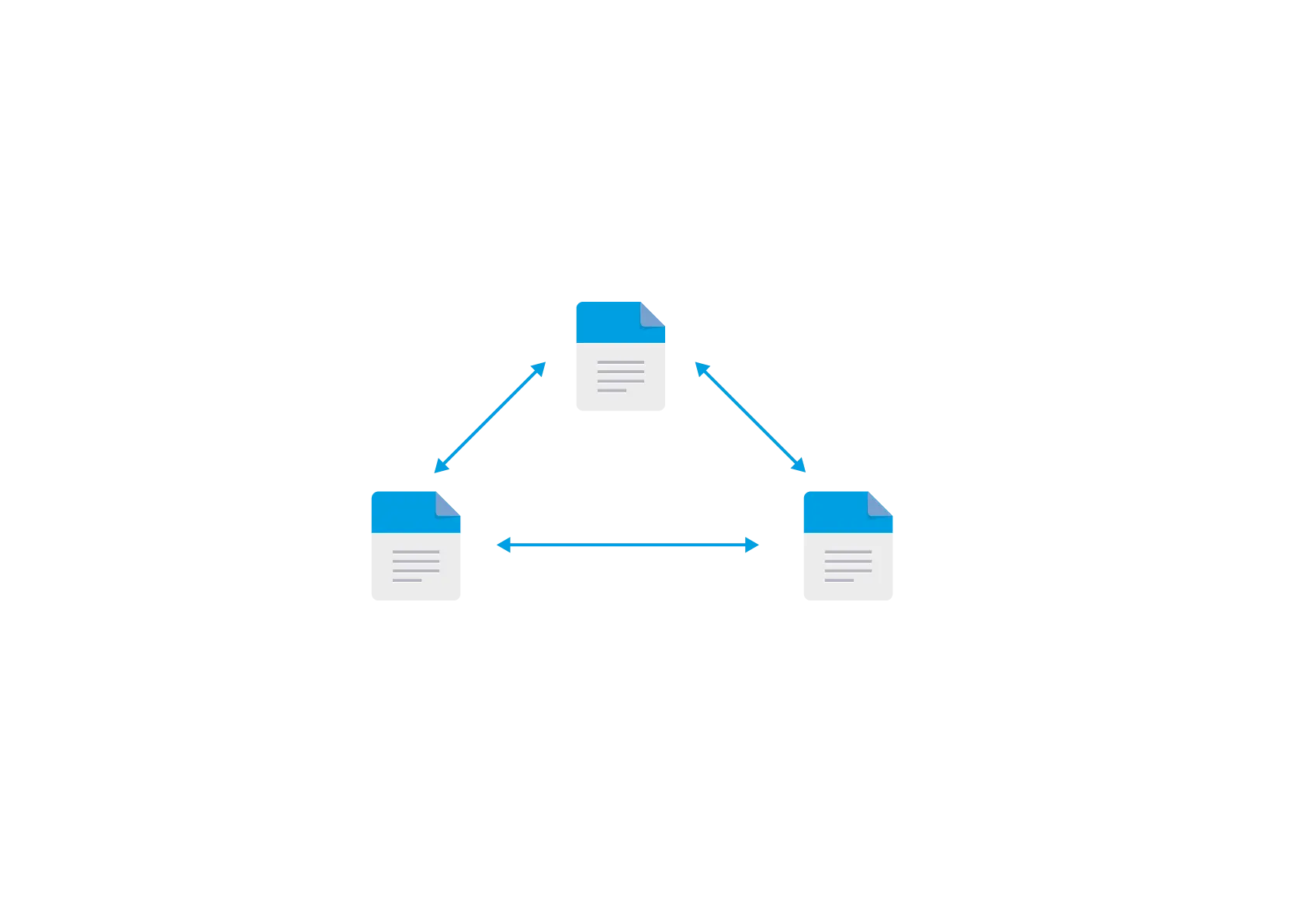
Multi-directional file replication. Anything that changes in one system is propagated to the other systems or virtual machines.
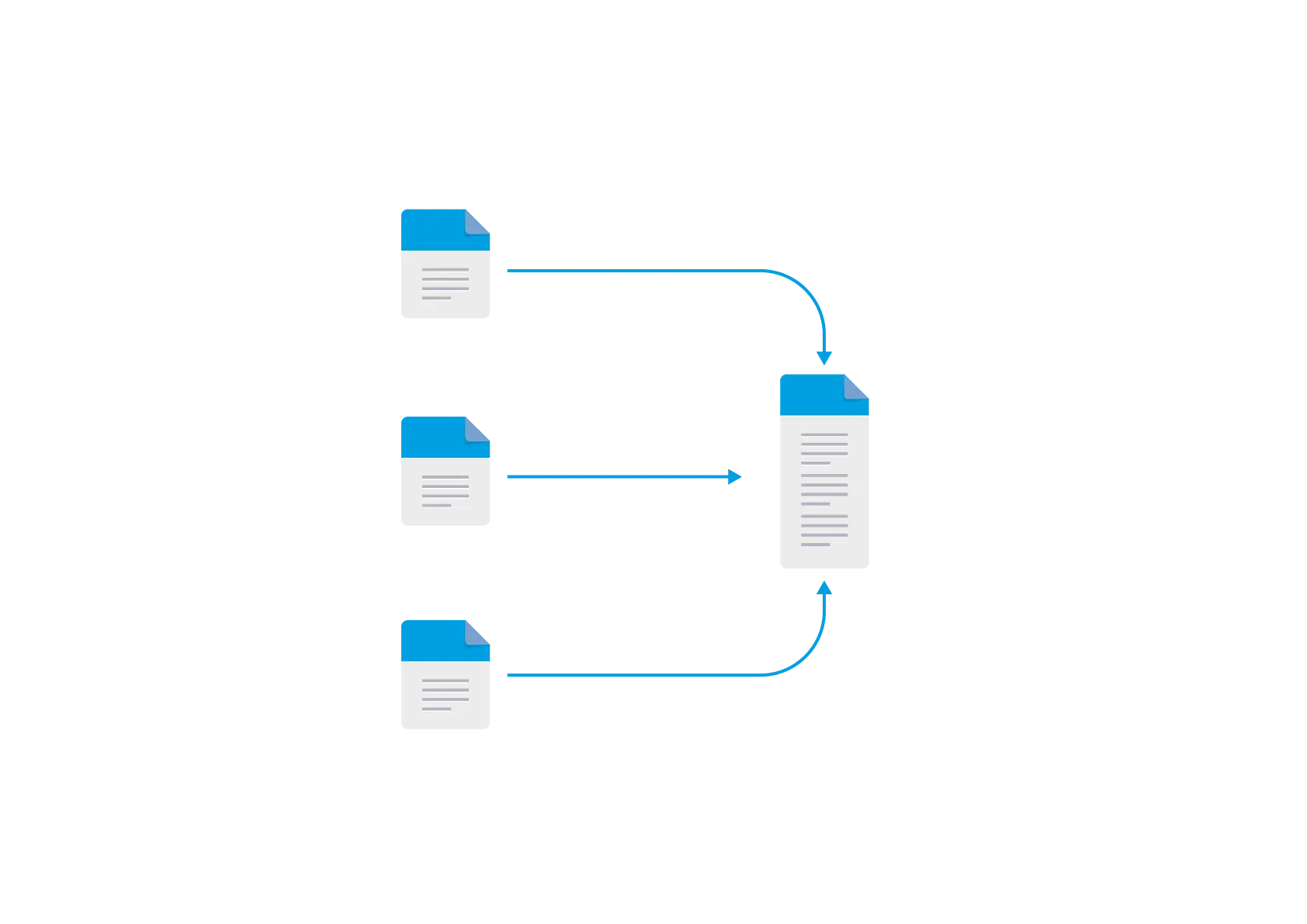
Any file changes that take place on any of the systems are propagated to one or more systems of VMs for consolidation or for data protection purposes.
Data flow and file replication with filtering policies
EDpCloud can be configured to send and replicate certain file patterns and/or exclude certain file patterns using regular expressions. Data can be passed to other applications for ingestion or other processing, as shown in the next figure. Additional information is shown in the infographic at the end of this article.
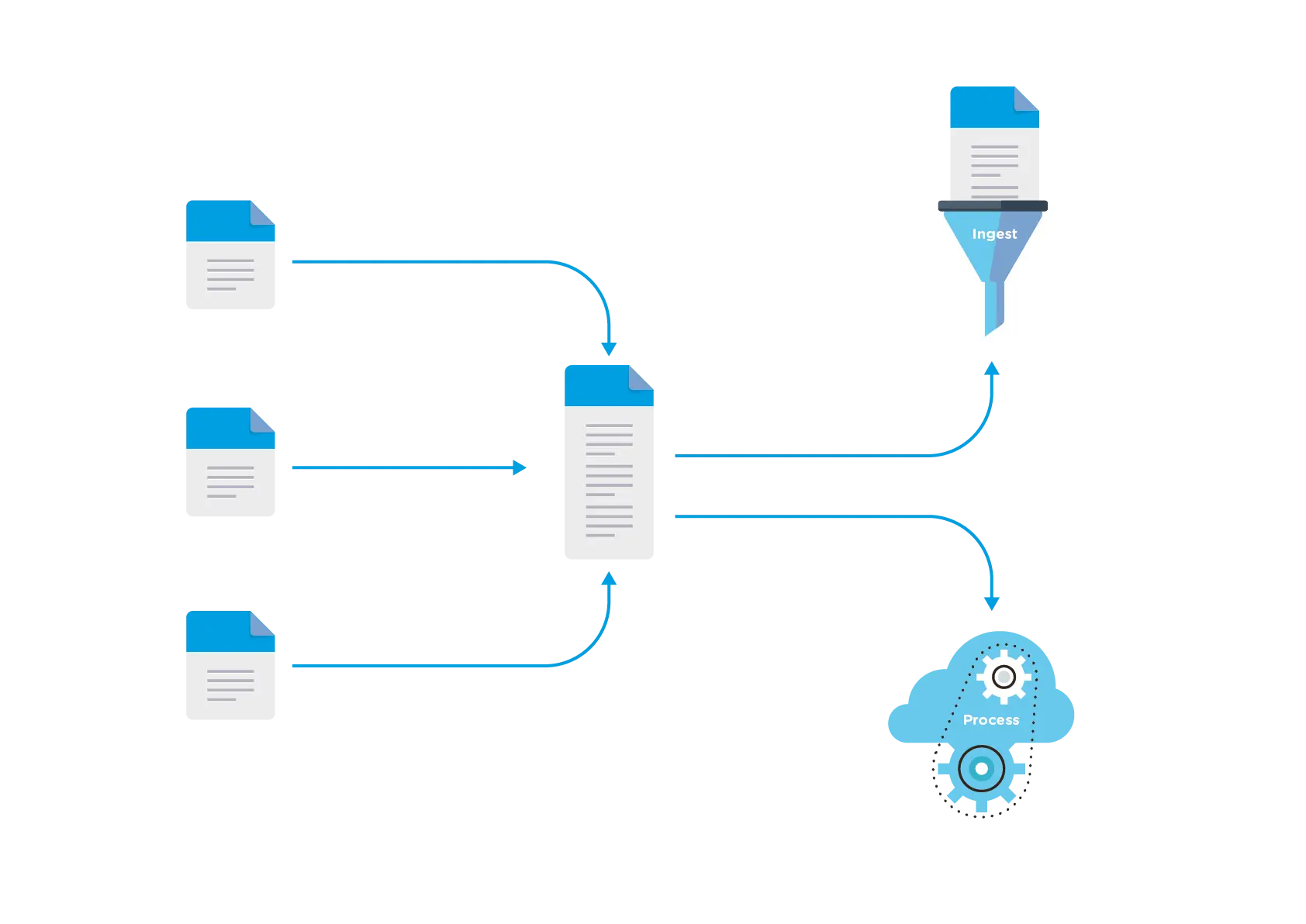
Pausing and resuming Data flow and transfer
System administrators can create schedules to pause and resume replication at specific times. When replication is paused, file changes continue to be logged, and replication will resume from where it left off after the replication resume command is invoked. Pause and resume of replication can be called from scripts, schedules, applications, or command lines.
Data flow between cloud providers